VMware vCenter Server (formerly VMware VirtualCenter)

VMware vCenter Server is the centralized monitoring and resource management software for VMware vSphere virtual infrastructure.
VMware vCenter Server performs a number of tasks, including resource provisioning and allocation, performance monitoring, workflow automation and user privilege management. It enables a vSphere administrator to manage multiple ESX and ESXi servers and virtual machines (VMs) through a single console.
Many key vSphere features, including VMware Distributed Resource Scheduler (DRS), vSphere High Availability (HA), vSphere Fault Tolerance (FT) and VMware vMotion, require vCenter Server to function.
VMware vCenter Server architecture
The vCenter Server architecture consists of three main components: vSphere Web Client, vCenter Server Database and vCenter Single Sign-On.
The vSphere Web Client is a web application that acts as the vCenter Server user interface. It enables the administrator to manage installation and handle inventory objects in a vSphere deployment and provides console access to VMs. VMware introduced a new HTML5-based vSphere Client in vSphere 6.5; the company said it would retire the Flash-based web client in the next numbered version of vSphere.
The vCenter Server Database stores and manages server data, from inventory items to resource pools. Every instance of vCenter Server requires its own unique database. Introduced in vSphere 5.1, vCenter Single Sign-On (SSO) is an authentication broker and security token that enables the user to use one login to access the entire vSphere infrastructure without further authentication.
Key features
Important vCenter Server features include the following:
Multi-hypervisor management. VMware vCenter Server offers integrated management for VMware and Microsoft Hyper-V hosts.
VMware Host Profiles. This tool automates ESX and ESXi host configuration. A vSphere administrator can use Host Profiles to create a standard configuration, which serves as a sort of blueprint for all other hosts, and automate compliance to this configuration across all hosts or clusters.
Automatic VM restart. VMware vCenter Server uses vSphere HA to pool VMs and their hosts into a cluster. In the event of a server failure, vSphere HA will automatically restart these VMs on other hosts within the cluster.
Patch management. The vSphere Update Manager (VUM) automatically scans and patches ESXi hosts and certain Microsoft and Linux VMs.
vRealize Orchestrator (vRO). This vCenter Server plug-in, which integrates with vRealize Suite and vCloud Suite, automates tasks using workflows.
vRealize Log Insight for vCenter Server. This log management software has customizable dashboards that enable an administrator to analyze system log data, identify and troubleshoot issues, and check for system compliance.
vCenter Server Linked Mode. This feature provides an administrator with a single view of their vSphere deployment. An administrator can also use Linked Mode to connect multiple vCenter Server systems and grant them permission to share information. Linked Mode automatically replicates all new resources created by the administrator, including roles, policies and permissions, across the linked vCenter Server systems.
Application programming interfaces (APIs). VMware vCenter Server uses APIs to communicate and integrate with third-party software.
Use cases
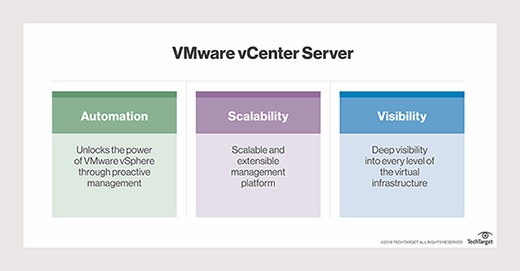
VMware vCenter Server has three primary uses cases: automation, visibility and scalability.
Tools such as a task scheduler and vRO automate a variety of processes to deliver proactive management capabilities. The variety of features in vCenter Server provide visibility throughout the virtual infrastructure, which makes it easier for a vSphere administrator to configure host servers and VMs and monitor performance. And this visibility is highly scalable and extensible thanks to Linked Mode.
Pros and cons of vCenter Server
According to VMware, vCenter Server streamlines VM deployment, enables an administrator to continuously monitor performance and prevents unauthorized access. Other benefits, the company said, are it automates workflows, minimizes the effects of system failures and simplifies integration with third-party products.
A single vCenter Server can manage thousands of VMs, and that number only increases when Linked Mode connects multiple instances. Although that capacity is impressive, it can also be a disadvantage. Because a vCenter Server database stores all server data, the more VMs on a single instance, the higher the risk of exceeding the database's limits, which would require the purchase of an additional vCenter Server.
Another drawback is, as of August 2017, VMware said it would deprecate vCenter Server for Windows in future releases of vSphere, replacing it with vCenter Server Appliance (vCSA) as the definitive deployment model. Although the Linux-based vCSA comes preconfigured and promises greater scalability, it can only run on virtual hardware and typically sits on the same hardware cluster as production VMs. Organizations can work around this issue by creating a separate management cluster for vCSA, but this requires additional hardware and licensing, which defeats the purpose of vCSA's purported cost-efficiency.
Different versions
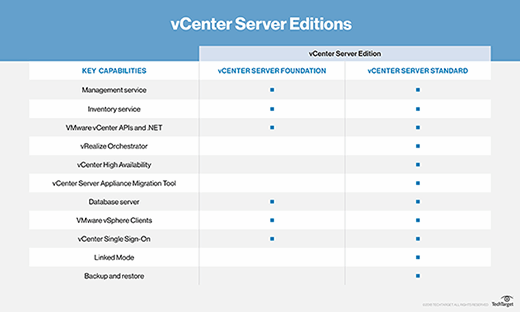
VMware offers two editions of vCenter Server: Foundation and Standard. VMware vCenter Server Foundation is intended for smaller infrastructures with up to four vSphere hosts, and vCenter Server Standard is designed for large-scale vSphere deployments and includes a larger number of capabilities.
Both licenses come with two support options: Basic and Production. The Basic support option offers technical support 12 hours per day within published business hours, Monday through Friday; the Production support option offers technical support 24 hours a day, seven days a week.